Simerse AI
Map Civil Infrastructure with Simerse AI
The Simerse Software Platform maps utility & municipality infrastructure using AI & mobile mapping technology.
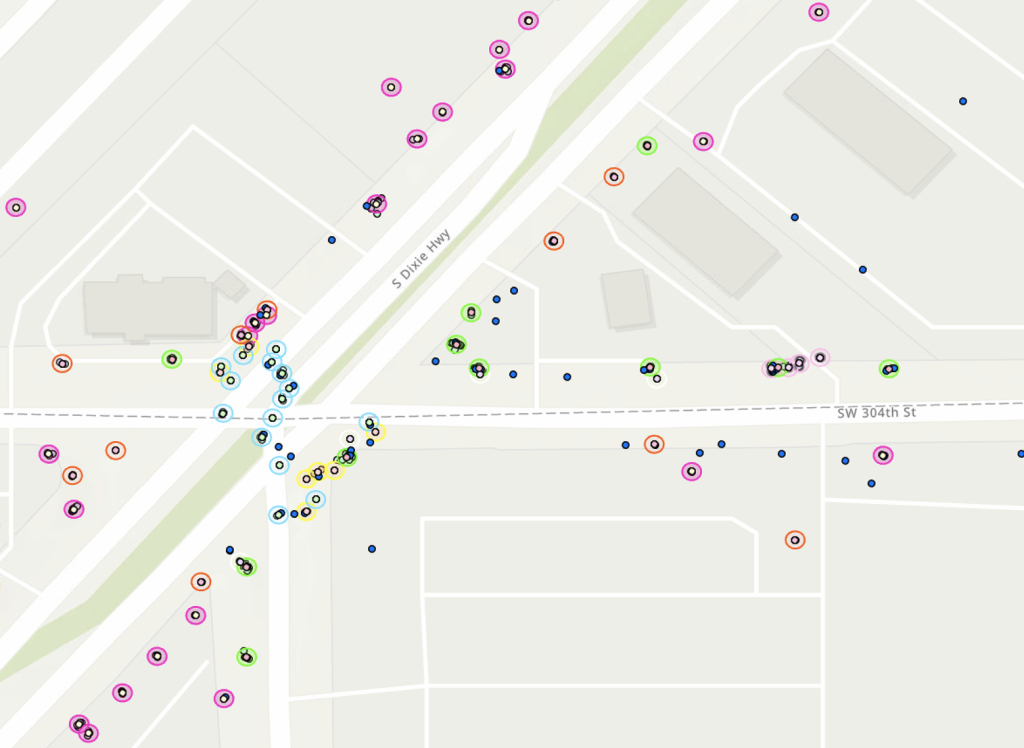
What we do
Simerse uses proprietary AI to find infrastructure & update records
Simerse saves time looking at infrastructure, so companies can build, operate, and maintain the field assets we rely on.
Electric Utilities
There are over five million miles of T&D power lines in the U.S. alone.
Public Works
Cities & counties need to catalogue millions of field assets.
State DoTs
In the U.S., there are over five billion meters of public roads.
Telecom
There are millions of miles of fiber & telecom lines in the US.
bringing a scalable solution to gis records
Simerse updates GIS records faster than traditional methods
Simerse’s ability to ingest & analyze 360° imagery & LiDAR data can outpace manual data collection & analysis.
Truck Rolls Take Time
There is a time cost to sending out manual teams.
Field Visits Are Expensive
It is expensive to manually map infrastructure. Simerse can help.
Need a Scalable Solution
Mobile 360° & LiDAR can map infrastructure assets at scale.
simerse ai is for the built environment
We need to track millions of infrastructure assets
Infrastructure is big. See how Simerse technology is helping to accurately map infrastructure field assets.
Field asset inventory
Updated location & condition records help cities run smoothly
Utilities & Municipalities need to know where field assets are. Simerse AI can help locate these field assets to real-world coordinates, enabling a more accurate view of your field inventory.

geo-databases
Energy grid infrastructure needs mapping
Manual field visits are time-consuming, expensive, and inefficient. Update your GIS fast with Simerse, capable of processing large volumes of vehicle or drone-collected data.
simerse ai is for the built environment
Here's the infrastructure Simerse maps
Simerse AI models are constantly being trained & upgraded.
Cities & Counties
- Traffic Signs
- Traffic Lights
- Street / Lane Markings
- Potholes
- Curbs
- Sidewalks
- ADA Ramps
- Waste Bins
- Fire Hydrant
- Pedestrian Signal
Electric Utilities
- Utility Power Pole
- Crossarms
- Pole-Mounted Transformers
- Pin Insulators
- Cutouts / Lightning Arrestors
- Switches
- Streetlight Attachment
- Joint Use Attachments
- Vegetation
- Pad-Mounted Transformers
New Assets
Simerse regularly adds requested assets to the data dictionary.
Step 1
Simerse ingests 360° mobile mapping images.
Simerse® Vision AI takes in data from 360° cameras and LiDAR point cloud scans.

Step 2
Simerse AI detects infrastructure assets.
Simerse® processes this data to extract key features and turn raw data into structured data.
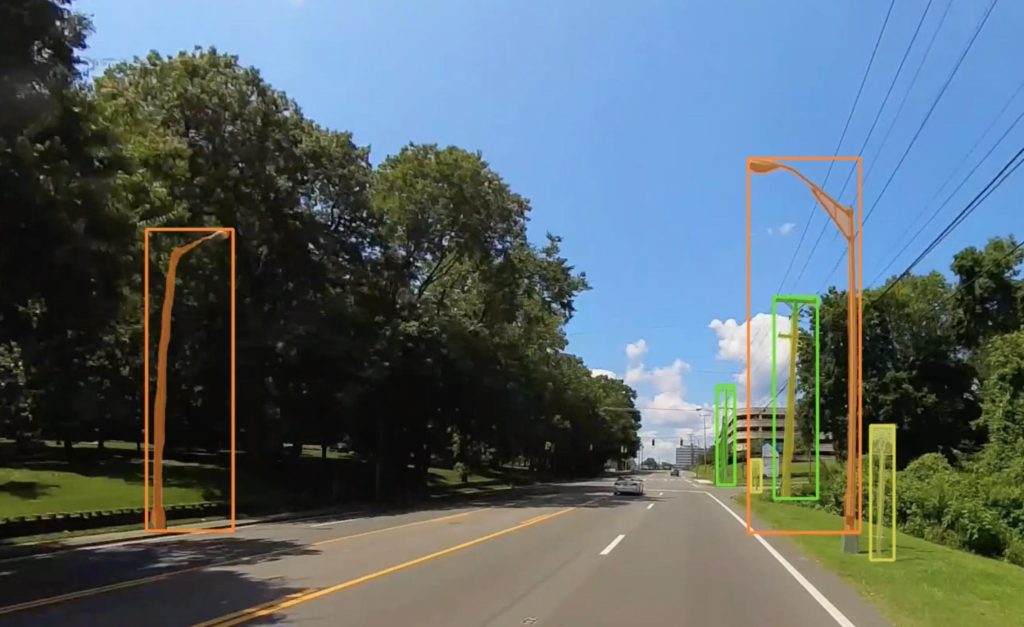
Step 3
Simerse AI derives location for each infrastructure asset.
Simerse® AI sends the features back to your GIS platform.
Industries
Who does Simerse help?
Simerse aims to improve infrastructure sectors through innovation.

for Utilities, Local Government, & telecom
Electric Utilities
Get up-to-date inventory of your field assets. Geolocate poles, transformers, and other high-value equipment.
- Geolocate Field Assets
- Get Accurate Grid Inventory
- Update GIS with Field Assets

for municipalities & Government
Cities & Public Works
Monitor key street-level infrastructure in public right-of-way, understand change over time, & inventory municipal assets with Simerse Vision AI.
- Traffic Signs
- Road Assets
- ADA Compliance

for telecom companies
Telecom & Fiber
Inventory fiber assets, track poles, and identify equipment with Simerse AI.
- Joint Use Attachments
- Pole Inventory
- Tower RAND Level Monitoring
simerse ai can help cities & utilities track their assets
Infrastructure is vast. Better asset records can help.
Simerse ingests imagery from vehicles, drones, or smartphones. Simerse AI then derives the locations for GIS.